
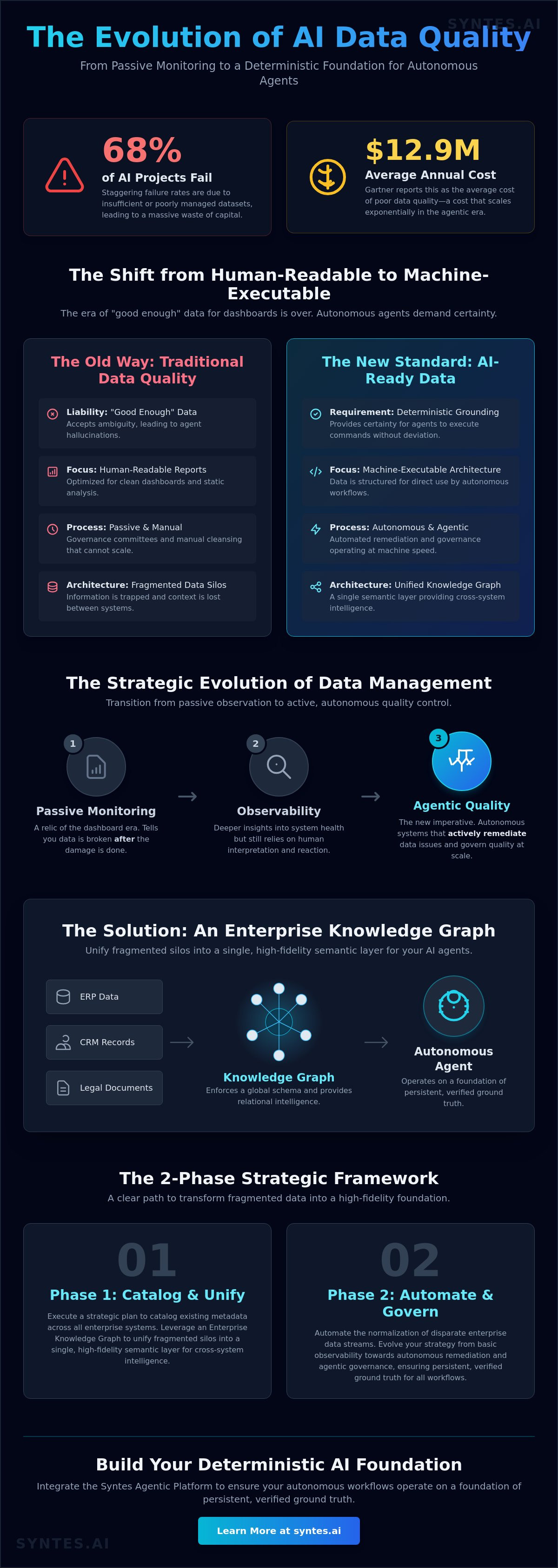
Industry data reveals that 68% of AI projects fail because of insufficient or poorly managed datasets. It’s a staggering waste of capital. While your competitors chase the latest model architecture, your actual bottleneck remains the fragmented, hallucination-prone sludge sitting in your legacy silos. Modern ai data quality management is no longer a passive maintenance task; it’s an active architectural requirement. You likely feel the weight of expensive, manual data cleansing that refuses to scale while your agents struggle to find a single source of ground truth.
We agree that the era of “good enough” data ended when the EU AI Act and Colorado AI Act introduced strict transparency and risk requirements for 2026. This article provides a comprehensive strategic framework to transform your fragmented silos into a high-fidelity foundation for autonomous AI agents. You’ll learn how to implement automated remediation at scale and move toward a deterministic data environment that eliminates operational risk. We will explore the transition from passive observation to active, automated performance through the lens of semantic knowledge graphs and integrated agentic workflows.
Key Takeaways
- Replace human-readable reports with machine-executable architectures that provide agents with precise, deterministic grounding.
- Leverage an Enterprise Knowledge Graph to unify fragmented silos into a single, high-fidelity semantic layer for cross-system intelligence.
- Evolve your strategy for ai data quality management from basic observability toward autonomous remediation and agentic governance.
- Execute a strategic two-phase framework to catalog existing metadata and automate the normalization of disparate enterprise data streams.
- Integrate the Syntes Agentic Platform to ensure your autonomous workflows operate on a foundation of persistent, verified ground truth.
The Crisis of “Good Enough” Data in the Agentic Era
Traditional data quality was built for human consumption. It focused on clean dashboards and tidy reports. That era is over. In a landscape dominated by autonomous agents, “good enough” data is a liability. It is the fuel for hallucination. AI data quality management (AIDQM) must now function as a deterministic framework for agent grounding. It is no longer about whether a human can understand a record; it is about whether a machine can execute a command based on that record without deviation. Accuracy is insufficient. We require certainty.
The distinction is binary. Traditional data quality is human-readable; AI-ready data is machine-executable. When an autonomous agent queries a database, it does not possess the tribal knowledge to “fill in the blanks” like a human analyst. It demands a high-fidelity foundation. Failure to provide this results in the “Hallucination Tax.” Gartner reports that poor data quality costs organizations an average of $12.9 million annually. In the agentic era, this cost scales exponentially as flawed data leads to autonomous errors in production environments. Enterprises in 2026 are abandoning probabilistic “best guesses” for deterministic data structures that guarantee reliability.
Why Traditional Data Governance Fails AI Agents
Manual governance cannot keep pace with agentic execution. It is a fundamental speed mismatch. While a governance committee meets monthly to discuss metadata standards, an agent performs thousands of cross-system operations per second. This latency creates a context gap. Isolated data points, stripped of their relational intelligence, lead to flawed reasoning. Legacy silos remain the primary inhibitors of reliability. They trap information in formats that agents cannot reconcile, forcing the model to guess rather than know. We see similar veracity challenges in the role of AI on platforms like Wikipedia, where automated content generation must struggle against the limits of its training data and grounding sources.
Defining the New Dimensions of AI-Ready Data
What defines high-fidelity data for ai data quality management? It starts with semantic density. This goes beyond record accuracy to include relational intelligence. The agent must understand how a customer record in a CRM relates to a contract in a legal database. Real-time relevance is equally critical. For an agent, stale data is wrong data. If the information is not current, the agent’s action is invalid. Finally, we must demand absolute traceability. Every output an agent generates must be traceable to a specific, verified data source. Without this lineage, the system remains a black box, and the operational risk remains unmanageable.
Transitioning from Passive Monitoring to Semantic Grounding
Passive monitoring is a relic of the dashboard era. It tells you that data is broken after the damage is done. In 2026, effective ai data quality management requires a shift toward semantic grounding. You can no longer rely on a “Data Lake” that acts as a digital swamp. You need a Knowledge Fabric. This is where the Enterprise Knowledge Graph becomes the definitive source of truth. It maps the complex relationships between entities that traditional relational databases simply ignore. By moving from isolated records to a connected knowledge layer, you provide the deterministic logic your agents need to act with certainty.
The Knowledge Graph: A Non-Negotiable for AI Reliability
Relational databases are blind to context. They store data in rigid rows and columns, but intelligence lives in the connections. A graph architecture links structured ERP data with unstructured legal documents into a single semantic layer. This provides the deterministic logic required for knowledge graph for llm grounding. Without this structure, your agents are merely guessing based on proximity. They lack the ontological guardrails to distinguish between a “customer” in a sales context and a “customer” in a legal dispute. Graphs eliminate this ambiguity by enforcing a global schema across all integrated systems.
Semantic Grounding vs. Vector Search
Vector search is the industry’s favorite shortcut. It’s useful but insufficient for enterprise-grade accuracy. Retrieval-Augmented Generation (RAG) relies on mathematical probability, which is why it still produces confident hallucinations. To achieve true ai model reliability, you must implement a deterministic layer to sanity-check AI outputs against a fixed ontology. By applying specific AI patterns for improving data quality, such as automated entity resolution and relationship mapping, you move beyond “probabilistic retrieval” to “deterministic intelligence.” This structural grounding ensures that an agent’s reasoning is anchored in verified facts rather than statistical likelihoods. Organizations looking to bridge this gap should evaluate how cross-system integrations can feed a unified knowledge layer to ensure total operational clarity.
Evaluating Your Infrastructure: Monitoring vs. Observability vs. Agentic Quality
Infrastructure is not a static asset. It’s a maturing capability. Most enterprises remain trapped in the lower tiers of the data quality hierarchy, performing basic unit testing or threshold-based monitoring. These methods are insufficient for the 2026 enterprise. Modern ai data quality management requires an evolution through four distinct phases: Testing, Monitoring, Observability, and finally, Agentic Governance. Testing validates known constraints. Monitoring tracks known failures. Observability discovers unknown anomalies. However, only Agentic Governance provides the deterministic control needed for autonomous agents. High-quality data remains foundational for AI success, but the definition of “quality” has shifted from static accuracy to active, self-healing reliability. You must assess where your current stack sits on this spectrum before deploying agentic workflows.
The Limits of Observability
Observability has its limits. It’s a diagnostic tool, not a cure. It identifies that a pipeline has stalled or that a schema has drifted, but it still requires human intervention to resolve the crisis. This manual intervention is the primary bottleneck in scaling enterprise AI. Agentic Governance changes this dynamic entirely. By deploying AI agents within the data pipeline itself, systems can achieve a state of self-healing. These agents don’t just report errors; they rectify them in real-time by cross-referencing sources and applying semantic rules. This marks the essential transition from human-in-the-loop to human-on-the-loop governance. You’re no longer the mechanic performing manual cleansing; you’re the architect of a system that maintains its own integrity through autonomous remediation.
Cross-System Integration: The Connectivity Requirement
Data quality is a network problem. It’s rarely confined to a single database or a localized cloud instance. When an agent executes a complex workflow, it must traverse a web of ERP, CRM, and legacy environments. If these systems aren’t unified, the agent’s reasoning collapses into a series of disconnected guesses. This connectivity is the backbone of effective ai data quality management. You can’t manage enterprise intelligence in a vacuum. The Syntes AI approach solves this by integrating disparate sources into a unified Enterprise Knowledge Graph. This creates a coherent agentic framework where data from every corner of the organization is normalized, verified, and ready for autonomous execution. Without this systemic integration, your agents are blind to the “ground truth” of your operations.
The 2026 AI Data Quality Checklist: A Strategic Framework
Execution is the only metric that matters. Theoretical frameworks are useless if they cannot survive the rigors of an autonomous production environment. To achieve deterministic intelligence, your ai data quality management strategy must move through five rigorous phases. This is not a suggestion; it is the new standard for enterprise survival in an agentic economy. Manual data cleansing is a failure of architecture. If your data requires human intervention to be “ready,” your system is already obsolete. Stop guessing. Start governing.
- Phase 1: Semantic Discovery & Mapping. Identify every data source. Catalog your metadata. You cannot govern what you haven’t mapped.
- Phase 2: Automated Cleansing & Normalization. Deploy agents to scrub the sludge. This agentic cleanup replaces manual ETL with real-time, self-correcting pipelines.
- Phase 3: Relational Grounding. Construct the Enterprise Knowledge Graph. Link disparate entities into a unified ontology to provide the deterministic logic your models demand.
- Phase 4: Continuous Observability & Self-Healing. Establish a feedback loop. Systems must detect drift and remediate it autonomously before it reaches the model.
- Phase 5: Policy Enforcement & Governance. Apply the security layer. Ensure compliance with the EU AI Act and Colorado AI Act by enforcing strict transparency and lineage rules.
Technical Readiness Checklist
Your infrastructure must be capable of supporting real-time intelligence. High latency is the enemy of agentic grounding. If your cross-system API calls take seconds rather than milliseconds, your agents will fail. Use this checklist to verify your technical foundation:
- Verify cross-system API latency is optimized for real-time agent grounding.
- Implement automated schema validation across all connected nodes to prevent downstream corruption.
- Ensure 100% lineage tracking for all data used in LLM prompts to meet 2026 regulatory standards.
Operational Governance Checklist
Governance is not a committee; it is a set of executable rules. You must define the boundaries of what your agents can and cannot do with your data. Without these guardrails, autonomous workflows become a liability. Audit your operational readiness with these steps:
- Establish a “Semantic Owner” for every core enterprise entity to ensure ontological consistency.
- Define deterministic guardrails for agentic data modification to prevent unauthorized schema changes.
- Audit AI response accuracy against the Knowledge Graph weekly to verify grounding integrity.
Effective ai data quality management requires more than a checklist; it demands a total architectural overhaul. Organizations ready to transition from fragmented silos to a high-fidelity foundation should deploy the Syntes Agentic Platform to orchestrate their data quality via autonomous knowledge graphs.
Syntes AI: Orchestrating Data Quality via Agentic Knowledge Graphs
Data quality is a dead end without a mechanism for execution. You can clean your records for eternity, but if that data doesn’t trigger precise, autonomous action, it’s just a tidy archive. The Syntes Agentic Platform is where ai data quality management evolves from a defensive posture into an offensive advantage. It isn’t just an observability tool; it’s a command center for enterprise intelligence. By anchoring every autonomous workflow in a native Enterprise Knowledge Graph, we provide the deterministic “Ground Truth” that agents require to perform at scale. This is the transition from passive data management to active operational intelligence.
Maintaining high-fidelity data requires more than localized cleaning. It demands systemic connectivity. Our Cross-System Integrations ensure that information flowing from ERP, CRM, and legacy environments is normalized and mapped in real-time. We’re moving the industry beyond toy chatbots. We’re building the infrastructure for the high-performance enterprise where data quality and execution are inseparable. This architectural rigor ensures that your ai data quality management strategy isn’t just about compliance; it’s about competitive velocity.
The Syntes Advantage: Deterministic AI
Hallucinations are the result of structural ambiguity. We eliminate them through structural semantic grounding. Our platform empowers agents to traverse silos with a unified context, ensuring every decision is anchored in verified relationships rather than statistical proximity. In our recent deployments, we’ve seen organizations transition from fragmented, contradictory silos to a unified agentic enterprise where data is no longer a bottleneck but a catalyst for growth. The result is a system that doesn’t just “think” it knows the answer; it possesses the structural proof to execute with certainty.
Future-Proofing Your AI Strategy
2026 is the year of the Agentic Knowledge Graph. The regulatory environment and the speed of the market no longer allow for probabilistic errors. You need a foundation that is as rigorous as your business logic. Starting your journey with Syntes AI means securing your competitive position in an autonomous future. It’s time to stop managing data and start orchestrating intelligence. The era of the digital swamp is over. The era of the knowledge fabric has arrived. Schedule a strategy session to unify your enterprise data and build your high-fidelity foundation today.
Architecting the Deterministic Enterprise
The transition from fragmented silos to agentic autonomy is no longer a theoretical exercise. It’s a survival requirement. Traditional observability has hit its limit, leaving enterprises to pay a heavy “Hallucination Tax” on every flawed AI output. True ai data quality management requires a fundamental shift toward structural semantic grounding. You must move beyond passive monitoring and embrace an architecture where data quality is machine-executable and self-healing. By implementing a deterministic foundation, you ensure that your agents operate on verified ground truth rather than statistical probability.
Success in 2026 demands more than just clean data. It demands a unified knowledge fabric. The Syntes Knowledge Graph provides the deterministic foundation your models need to navigate complex, cross-system environments with absolute certainty. Our platform delivers enterprise-grade integration at scale, designed specifically for the rigors of autonomous operations. Don’t let legacy silos compromise your AI strategy. Deploy the Syntes Agentic Platform to unify your enterprise intelligence. The path to total operational clarity starts with a high-fidelity foundation. Build it now.
Frequently Asked Questions
What is the difference between traditional data quality and AI data quality management?
Traditional data quality ensures information is tidy for human analysts. AI data quality management ensures information is executable for autonomous agents. It moves beyond static record accuracy to focus on deterministic grounding and machine-ready schemas. While traditional methods report on past failures, this framework provides the high-fidelity foundation required for real-time AI reasoning and systemic integration.
How does a Knowledge Graph improve AI model reliability?
A Knowledge Graph provides the structural logic that large language models lack. It maps complex relationships across disparate systems, creating a unified semantic layer. This architecture forces the model to cite verified facts rather than relying on statistical proximity. By replacing probabilistic guesses with deterministic truth, it eliminates the ambiguity that compromises enterprise AI reliability.
Can AI agents manage their own data quality?
Agentic governance allows systems to achieve self-healing capabilities. AI agents don’t just observe data pipelines; they actively remediate them. By leveraging cross-system integrations, these agents can cross-reference sources and apply semantic rules to correct errors autonomously. This transition reduces manual cleansing costs and ensures that data remains ready for high-velocity execution.
What are the main causes of AI hallucinations in enterprise environments?
Hallucinations stem from a lack of grounding. When enterprise data is trapped in isolated silos, AI models struggle to find the ground truth. They attempt to bridge context gaps using mathematical likelihoods rather than verified facts. This probabilistic failure occurs when there’s no deterministic layer to sanity check the model’s reasoning against the organization’s actual operational logic.
How do I integrate legacy systems into an AI data governance framework?
Integration begins with semantic mapping. You must ingest metadata from legacy ERP and CRM systems into a unified Knowledge Graph. This process normalizes disparate data streams without requiring a total infrastructure overhaul. It creates a coherent agentic framework where agents can access legacy records with the same precision as modern cloud-native data.
Is data observability enough for agentic AI platforms?
Observability is a diagnostic tool, not a resolution strategy. It tells you that a pipeline is broken but requires a human to fix it. Agentic AI platforms demand more. They require an active governance layer that can detect drift and apply corrections in real-time. Without this autonomous remediation, your AI infrastructure remains tethered to slow, manual human intervention.
How does semantic grounding differ from standard RAG?
Standard RAG relies on vector search and mathematical similarity. Semantic grounding relies on a fixed ontology and deterministic logic. While RAG retrieves information that looks correct, semantic grounding verifies it against a Knowledge Graph. This ensures that the agent’s output is anchored in a verified structure, reducing the risk of confident but incorrect responses.
What is the ROI of investing in AI data quality management?
Investing in ai data quality management eliminates the Hallucination Tax and prevents the 68% failure rate common in poorly managed AI projects. It addresses the average $12.9 million annual cost of poor data quality reported by Gartner. The true return is operational velocity. High-fidelity data allows you to scale autonomous agents that perform complex tasks without constant human oversight. Organizations deploying secure enterprise AI architectures built on deterministic truth are best positioned to eliminate these costs while maintaining full visibility into every autonomous agent action.




